
Our method improves segmentation quality while significantly reducing token usage. A suite of metrics is introduced for holistic evaluations of reasoning quality, segmentation accuracy, and computational efficiency.
Abstract
Existing reasoning segmentation approaches typically fine-tune multimodal large language models (MLLMs) using image-text pairs and corresponding mask labels. However, they exhibit limited generalization to out-of-distribution scenarios without an explicit reasoning process. Although recent efforts leverage reinforcement learning through group-relative policy optimization (GRPO) to enhance reasoning ability, they often suffer from overthinking—producing uniformly verbose reasoning chains irrespective of task complexity. This results in elevated computational costs and limited control over reasoning quality. To address this problem, we propose PixelThink, a simple yet effective scheme that integrates externally estimated task difficulty and internally measured model uncertainty to regulate reasoning generation within a reinforcement learning paradigm. The model learns to compress reasoning length in accordance with scene complexity and predictive confidence. To support comprehensive evaluation, we introduce ReasonSeg-Diff, an extended benchmark with annotated reasoning references and difficulty scores, along with a suite of metrics designed to assess segmentation accuracy, reasoning quality, and efficiency jointly. Experimental results demonstrate that the proposed approach improves both reasoning efficiency and overall segmentation performance. Our work contributes novel perspectives towards efficient and interpretable multimodal understanding.
Comparison between PixelThink and Seg-Zero

Methodology
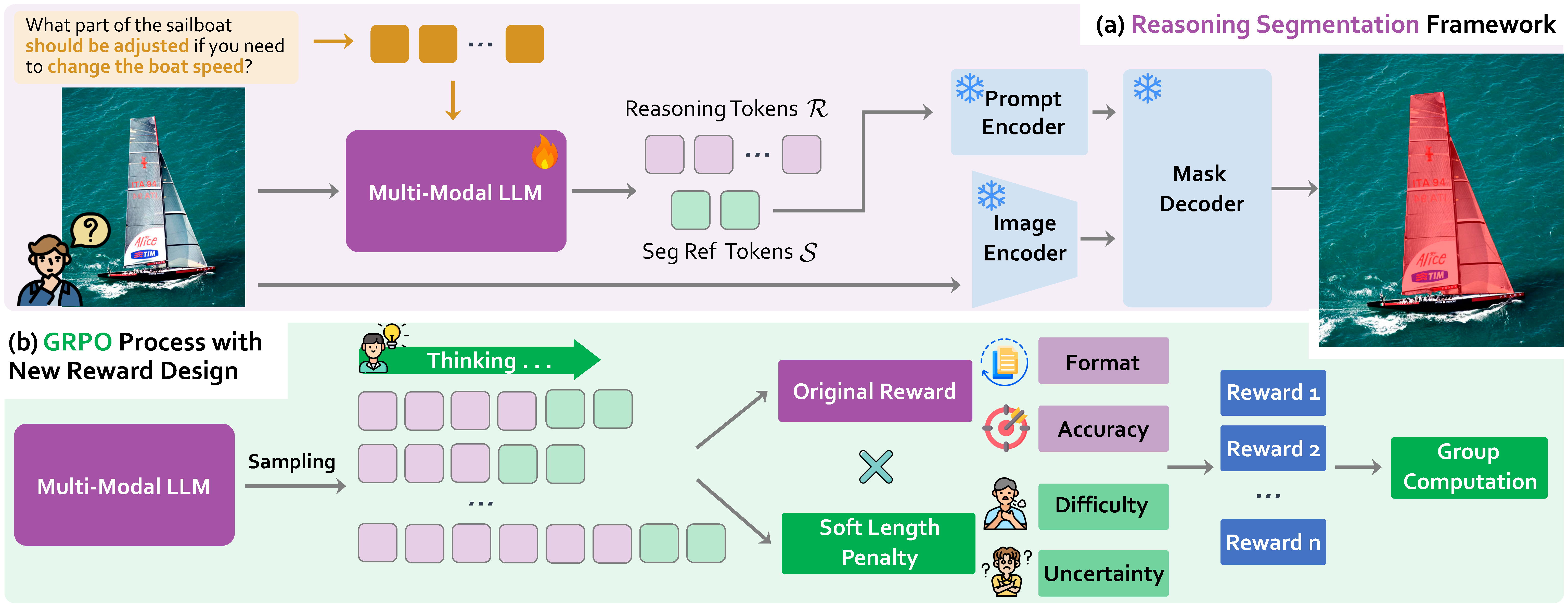
Overview of PixelThink. (a) Workflow of the reasoning segmentation framework. Given an input image and query, the model generates a reasoning chain and segmentation reference that guides the segmentation outcome. (b) The group-relative policy optimization (GRPO) procedure employed during reinforcement fine-tuning. Our new reward design incorporates both task difficulty and model uncertainty, enabling the model to learn efficient reasoning strategies
Benchmark Construction

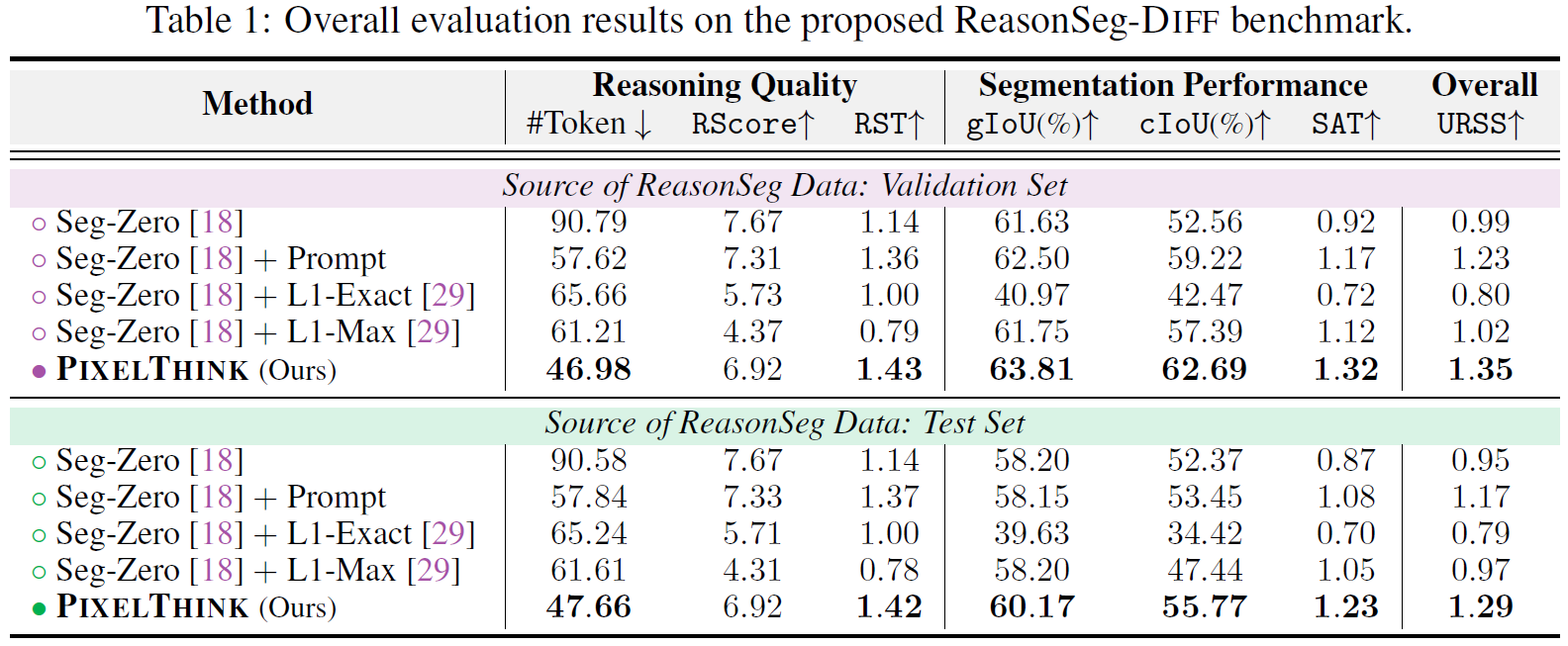
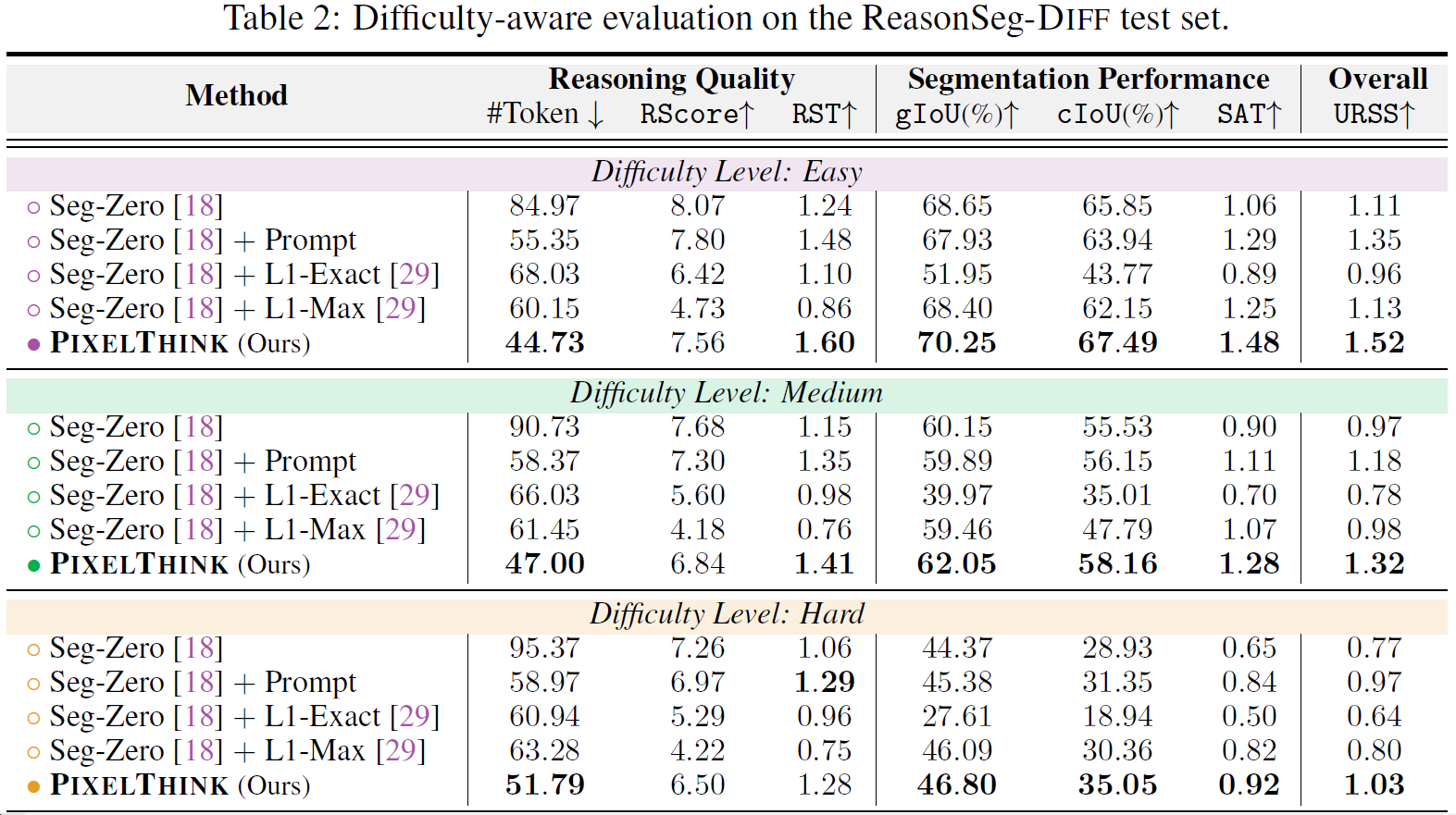
Quantitative Results
BibTeX
@article{wang2025pixelthink,
title = {PixelThink: Towards Efficient Chain-of-Pixel Reasoning},
author = {Wang, Song and Fang, Gongfan and Kong, Lingdong and Li, Xiangtai and Xu, Jianyun and Yang, Sheng and Li, Qiang and Zhu, Jianke and Wang, Xinchao},
journal = {arXiv preprint arXiv:2505.23727},
year = {2025},
}